Anthropic dropped Claude Sonnet 4.6 yesterday, and the benchmark numbers tell a compelling story: this mid-tier model now delivers roughly 98% of Opus 4.6’s performance on coding and computer use — at one-fifth the price.
The Numbers
The headline benchmarks:
- SWE-bench Verified: 79.6% — only 1.2 points behind Opus 4.6 (80.8%), ahead of GPT-5.2 (~78%)
- OSWorld (Computer Use): 72.5% — essentially matching Opus 4.6 (72.7%), crushing GPT-5.2 (38.2%)
- Math: 89% — a 27-point jump from Sonnet 4.5’s 62%
- ARC-AGI-2: 60.4% — up from 13.6 in the prior version
- Finance Agent v1.1: 63.3% — actually leading all models including Opus
The full comparison across 14 benchmarks shows Sonnet 4.6 trading blows with models that cost 2-5x more:
For the launch context and headline claims, here’s the announcement snapshot I referenced while writing this post:
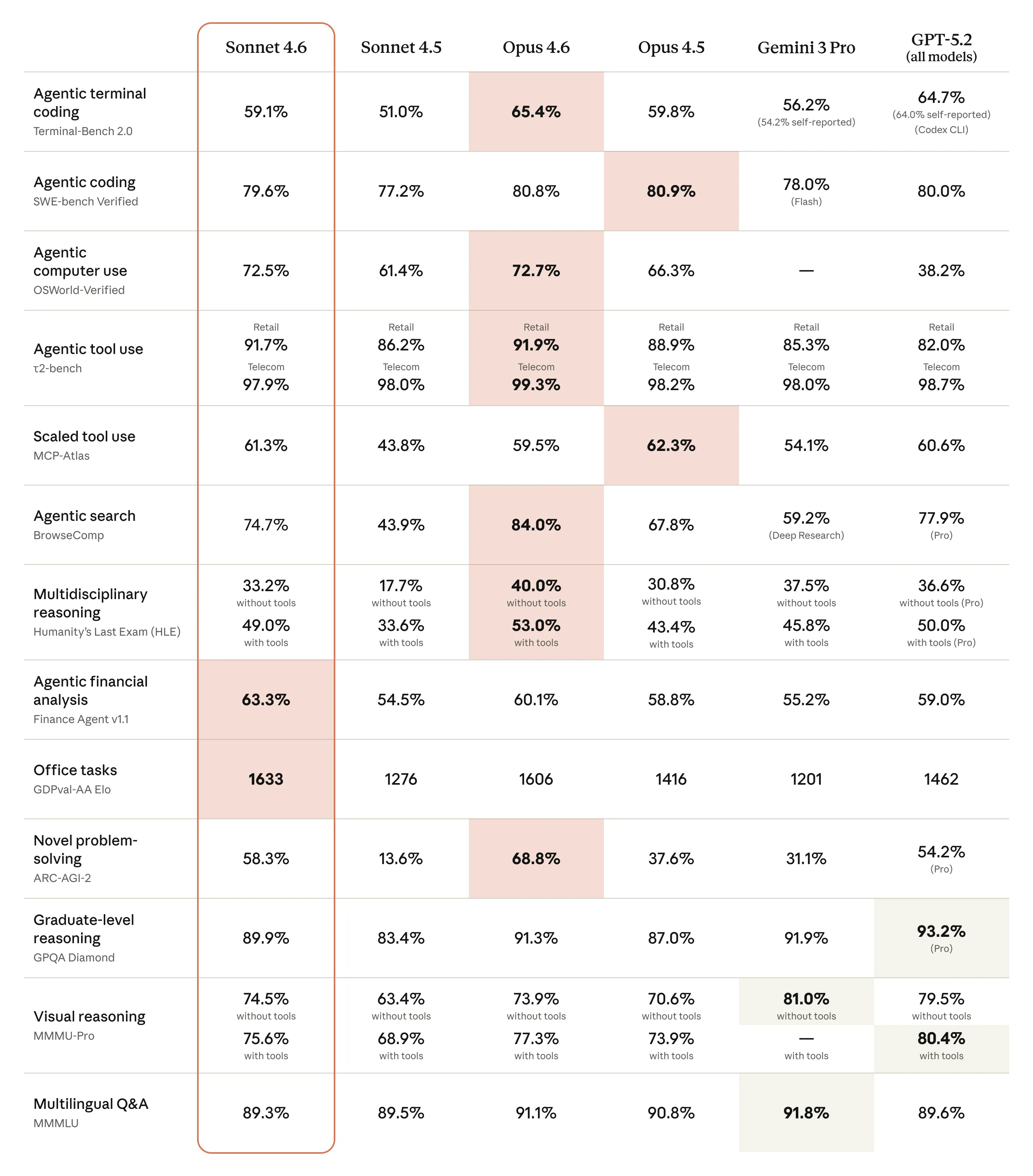
Where Opus still clearly leads is deep scientific reasoning (GPQA Diamond: 91.3% vs 74.1%) and agentic search (BrowseComp: 84.0% vs 61.7%). For pure research and complex multi-step reasoning, Opus justifies its price. For everything else? Sonnet 4.6 is remarkably close.
Computer Use: The Trajectory Matters
The most striking story might be the computer use progression. OSWorld measures a model’s ability to navigate real software — Chrome, LibreOffice, VS Code — using virtual mouse and keyboard, just like a human would.
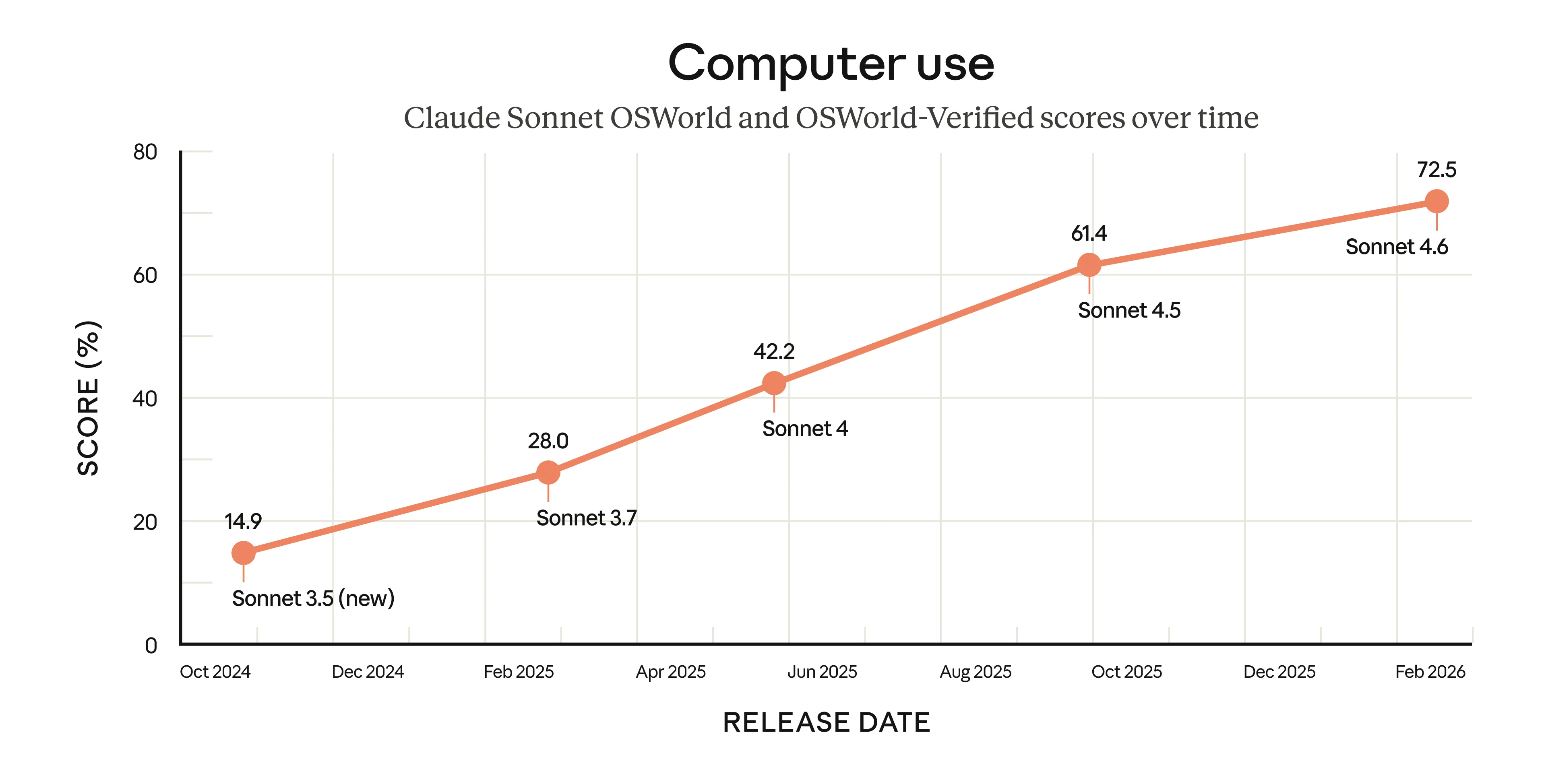
From 14.9% in October 2024 to 72.5% in February 2026. Nearly 5× improvement in 16 months. This is the metric that matters most for agentic workflows — AI navigating GUIs, filling forms, clicking through multi-step tasks across multiple browser tabs.
Early users are reporting human-level capability on tasks like navigating complex spreadsheets and multi-step web forms. The model still lags behind skilled humans, but the rate of improvement is remarkable.
What This Means for Builders
The “reach for Opus” decision just got a lot harder to justify for most coding and agentic use cases. At $3/$15 per million tokens (vs Opus at $15/$75), Sonnet 4.6 is the sweet spot for:
- Agentic coding at scale — 79.6% on SWE-bench with 80% cost savings
- Computer use agents — near-parity with Opus at 72.5% OSWorld
- Document comprehension — matches Opus on OfficeQA
- Financial analysis — actually leads all models at 63.3%
In Claude Code testing, developers preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time, and over the previous flagship Opus 4.5 59% of the time. They reported less overengineering, fewer false claims of success, and more consistent follow-through on multi-step tasks.
Two Things Worth Noting
1M Token Context Window
Sonnet 4.6 introduces a 1M token context window in beta — the first for any Sonnet-class model. Full codebase analysis in a single prompt is now practical at mid-tier pricing. Combined with the new context compaction feature (which automatically summarizes older context as conversations approach limits), this makes long-horizon planning and large-scale code review significantly more accessible.
Safety and Prompt Injection
Anthropic classifies Sonnet 4.6 under ASL-3 (AI Safety Level 3), acknowledging that “confidently ruling out capability thresholds is becoming increasingly difficult.” This isn’t alarmist — it’s honest about where we are as these models approach and surpass high levels of capability.
More practically relevant: prompt injection resistance now matches Opus. This matters enormously for computer use, where models interact with untrusted web content. When your AI agent is browsing websites and filling forms, resistance to hidden malicious instructions isn’t a nice-to-have — it’s essential. Good security practice means taking this seriously as we deploy these models in production.
The Bottom Line
The gap between “flagship” and “workhorse” models is closing fast. Sonnet 4.6 outperforms on orchestration evals, handles complex agentic workloads, and keeps improving the higher you push the effort settings. For most production coding and agentic workflows, the workhorse just won.
The interesting question isn’t whether Sonnet 4.6 is good enough — it clearly is. It’s what happens when this level of capability becomes the baseline that everyone builds on.